As it is now, we clearly see that the bridge can’t recover from a technical problem. Either orchestrators don’t care or they don’t have the technical capabilities to catch up.
We should discuss a new ceremony and a new way to calculate the minimum orchestrators needed to run the bridge. Something that’s not a strict % could work if a similar situation happens again.
Let’s say we have 70 orchestrators then the minimum for the bridge to run could be 10. It’s a lower percents than what’s needed now and yet a higher amount of nodes.
Anyway this gap between the needs for the bridge to be up and running and the seriousness and / or technical skills of the orchestrators should be addressed. Right now it just doesn’t work. Good we could benchmark it when there’s no real pressure to transact, capital wise.
I think many orchestrators are proactively deciding NOT to turn their equipment back on. The TSS Zero Day needs to be fixed.
I’ve very carefully looked at all the orchestrators, one by one. And I’ve talked to many. Here is why the bridge is down:
Operators can be online, but they elect to be off because of the TSS Zero Day.
One Operator has an issue with an IP address changing and can no longer join the pool. However, his Orchestrator is online, it just cannot be reached.
Other operators are still syncing their pillars. George has been syncing for 5 days (from scratch) and he is about 50% complete. Pillars should not bootstrap from my backup and have elected to sync from scratch.
IMO, the real issue is we need to implement libp2p or an IBD solution to improve sync times.
I think I was referring to this. Some of the Orchestrators that are down are very skilled software developers and they are offline for a reason, not because they do not care.
My guess is the Orchestrators that are offline and also have an offline Pillars are still syncing (like 707). But others that have Pillars that are up (Moonbazze for example) with an offline Orchestrator are off for a reason.
I do think we will need a new ceremony after the sync is done. Operators need to make sure they have a static IP that will not change. Also, it’s not easy to add orchestrators to the Keygen. If you recall, we had about 35 eligible orchestrators but only 22 were able to stay in sync in order to perform the Keygen. Many factors impact an Orchestrator’s ability to participate. So even if we had 50 Orchestrators trying to participate, my guess is 30 could be in sync for a keygen.
I think early on we realized that many Operators were restarting their znnd node every few hours because of the memory leak. On top of restarting, nodes should just restart themselves due to the memory issue. The Orchestrator relies on the znnd node being up. If the node goes down, the Orchestrator restarts causing it to be out of sync. I think that was the largest issue.
Now that we’ve fixed the memory issue I am curious to see how many can stay in sync. Maybe we can get a lot more in there.
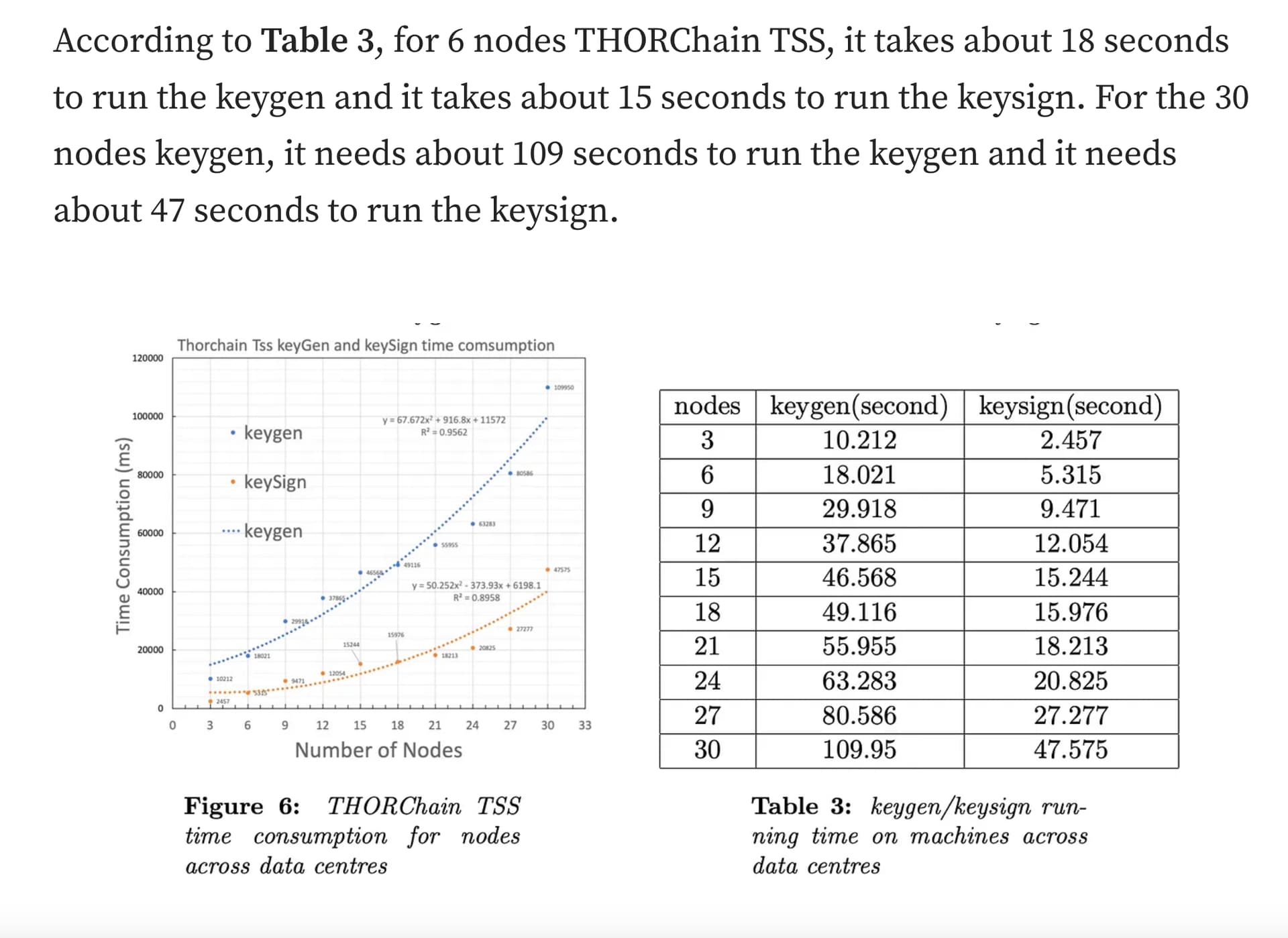
Keep in mind the time to generate a key goes up exponentially with the number of participants. Look at this study by THORChain. Not sure how this translates to our situation, but directionally I think it’s similar.
What makes it hard for an orchestrators to compute this ? It’s highly CPU demanding ? Doesn’t seem to be that long, unless there’s a very short window for nodes to send the results. If yes, the window could be extended.
I’m all for a new signing ceremony to allow new orchestrators to join - but I’d suggest it be aligned with the 0day patch and the majority of nodes being fully synched again
lowering the threshold for number of online Orchs requirements I’m not sure about, I’d like to hear @sumamu thoughts on it as to why 66% +1 was chosen and what risk it attempts to mitigate - it does seem like a relatively high threshold to meet